This post is from guest contributor Steve Lattanzio from MetaMetrics. While we do not tend to cover college rankings at e-Literate, we do care about transparency in usage of data as well as understanding opportunities where technology and data might inform students, faculty, administrators and the general educational community. The following post is an interesting exploration in the usage of the full set of College Scorecard data in a way that is understandable and usable. For people wanting a deeper description of the algorithms and assumptions, please see this corresponding article. For access to an interactive table to explore results, see this post.- ed
Emphasis on might.
Ranking colleges has become a bit of a national pastime. There are many organizations that publish “overall” rankings for our institutions of higher education (such as Forbes, Niche, Times Higher Education, and US News & World Report), each with their own methodologies.
We don’t typically get the complete and precise picture of how these rankings are constructed. The common assertion by critics is that these methodologies, which are definitely subjective, are also quite arbitrary. They may seem complex, often relying on many different variables, but at the end of the day experts and other higher education authorities are making a set of choices about what data should be used and how to weigh those variables. What if those experts were just tweaking what variables to include and how to weigh them until they got results that “feel right” or meet some other criteria they had in mind? Some methodologies go a bit further and outright include human judgments, sounding the fudge-factor alarm. Furthermore, there is reason to be concerned about the fact that none of these rankings exist in a vacuum—it’s very possible that they are, to some extent, reflections of each other (see “herding” in the polling industry). At the same time and counter to herding, there’s a desire to provide a unique twist to rankings which leads to a lack of consensus about what the underlying construct should be behind overall college rankings.
Against this backdrop, we now have access to ever-increasing amounts of data about our colleges. Newly released datasets like the College Scorecard present a vast trove of data to the public, enabling all sorts of new analytics. But while this provides an apparently more objective foundation for analysis, leveraging all of the data can be challenging.
This led MetaMetrics to consider whether we could apply some more current machine learning methods to overcome these issues, the type of methods that we employ everyday in our K-12 research. Was it possible to have a computer algorithm take in a bunch of raw data and, through a sufficiently black-box approach, remove decision points that allow ratings to become subjective? Forgive me the gratuitous use of such a buzzword, but could an artificial intelligence discover a latent dimension hidden behind all the noise that was driving data points such as SAT scores, admission rates, earnings, loan repayment rates, and a thousand other things, instead of combining just a few of them in a subjective fashion?
Out of an abundance of concern that the results of this experiment would be misrepresented, we’ll immediately point out that we make no claim that the rankings in this piece are the proper method for ranking these institutions, and we caution anyone from thinking of them as such. It is merely an alternative that we present that might be similar enough to other rankings to validate them, or different enough to invalidate them or this ranking. It is also possible that ranking colleges is an exercise in futility.
The data
Choosing a college is likely to be one of the most consequential decisions, financially and otherwise, of a postsecondary education consumer’s life. In an attempt to bring transparency to higher education and empower young Americans to make a more informed choice, the Obama administration created the College Scorecard in 2015.
The College Scorecard contains thousands of variables for thousands of schools going back almost two decades. It’s a great initiative that allows someone to look at all of the usual suspects, such as average SAT scores, along with very specific things, such as the “percent of not-first-generation students who transferred to a 4-year institution and were still enrolled within 2 years.” The catch, however, is that there is a lot of missing data and only a minority of the possible data elements actually exist. It’s fairly straightforward to search, filter, or sort by specific fields of information for specific schools, but it’s not really clear how you could utilize all of the data. Consequently, most analytic efforts with the College Scorecard are likely to gravitate towards the archetypal and complete variables you would find in a much less ambitious dataset anyway. Our goal is to take advantage of all of the data available in the College Scorecard.
The algorithm
Traditional statistical analyses work best with clean and complete data that have nice linear relationships. These analyses are also going to have trouble handling too many variables at once. But cleaning and curating specific variables in the dataset present more opportunities for humans to unduly (wittingly or not) impact the final results.
We also find ourselves lacking an independent variable to model. That is, we aren’t trying to predict one piece of data from a bunch of other data. We built an algorithm to find something not directly observable in the data that’s a driving force behind a lot of the directly observable things in the data. In machine learning, such a task is considered to be “unsupervised learning.”
To tackle this problem, we use neural networks1 to perform “representational learning” through the use of what is called a stacked autoencoder. I’ll skip over the technical details, but the concept behind representational learning is to take a bunch of information that is represented in a lot of variables, or dimensions, and represent as much of the original information as possible with a lot fewer dimensions. In a stacked neural network autoencoder, data entering into the network is squashed down into fewer and fewer dimensions on one side and squeezed through a bottleneck. On the other side of the network, that squashed information is unpacked in an attempt to reconstruct the original data. Naturally, information is lost during this process, but it’s lost in a deliberate fashion as the AI learns how it can combine the raw variables into new, more efficient, variables that it can push through a bottleneck consisting of fewer channels and still reconstruct as much of the original data as possible. To be clear, the AI isn’t figuring out which subset of variables it wants to keep and which it wants to discard; it is figuring out how to express as much of the original data as possible in brand new meta-variables that it is concocting by combining the original data in creative ways. As noise and redundancies are squeezed out over the many layers of the deep neural network, the hope is that a set of underlying dimensions – ones that represent the most important, overarching features of the data – emerge from the chaos, with one being a candidate for overall college quality.
The results
The nature and context of the representational learning problem dictates how far you can reasonably compress a dataset. In this case, it’s reasonable to compress to as few dimensions as possible where the meanings of the dimensions are still interpretable and we retain some amount of broad ability to reconstruct the original data.
It turns out that we were able to compress all of the information down to just two dimensions, and the significance of those two dimensions was immediately clear.
One dimension has encoded a latent dimension that is related to things such as the size of the school and whether it is public or private (in fact, the algorithm decided there should be a rift mostly separating larger public institutions from smaller schools). The other dimension is a strong candidate for overall quality of a school and is correlated with all of the standard indicators of quality. It seems as if the algorithm learned that for higher education, if you must break it down into two things, is best broken down into two dimensions that can loosely be described as quantity and quality.
Below are the top 20 colleges according to the AI and the resultant two dimensions.
|
1. |
Duke University |
11. |
College of William and Mary |
|
2. |
Stanford University |
12. |
University of Southern California |
|
3. |
Vanderbilt University |
13. |
Wesleyan University |
|
4. |
Cornell University |
14. |
Yale University |
|
5. |
Brown University |
15. |
Massachusetts Institute of Technology |
|
6. |
Emory University |
16. |
Northwestern University |
|
7. |
University of Virginia |
17. |
Bucknell University |
|
8. |
University of Chicago |
18. |
University of Pennsylvania |
|
9. |
Boston College |
19. |
Santa Clara University |
|
10. |
University of Notre Dame |
20. |
Carnegie Mellon University |
|
Top 20 Colleges in the United States, according to our AI.2,3 |
|||
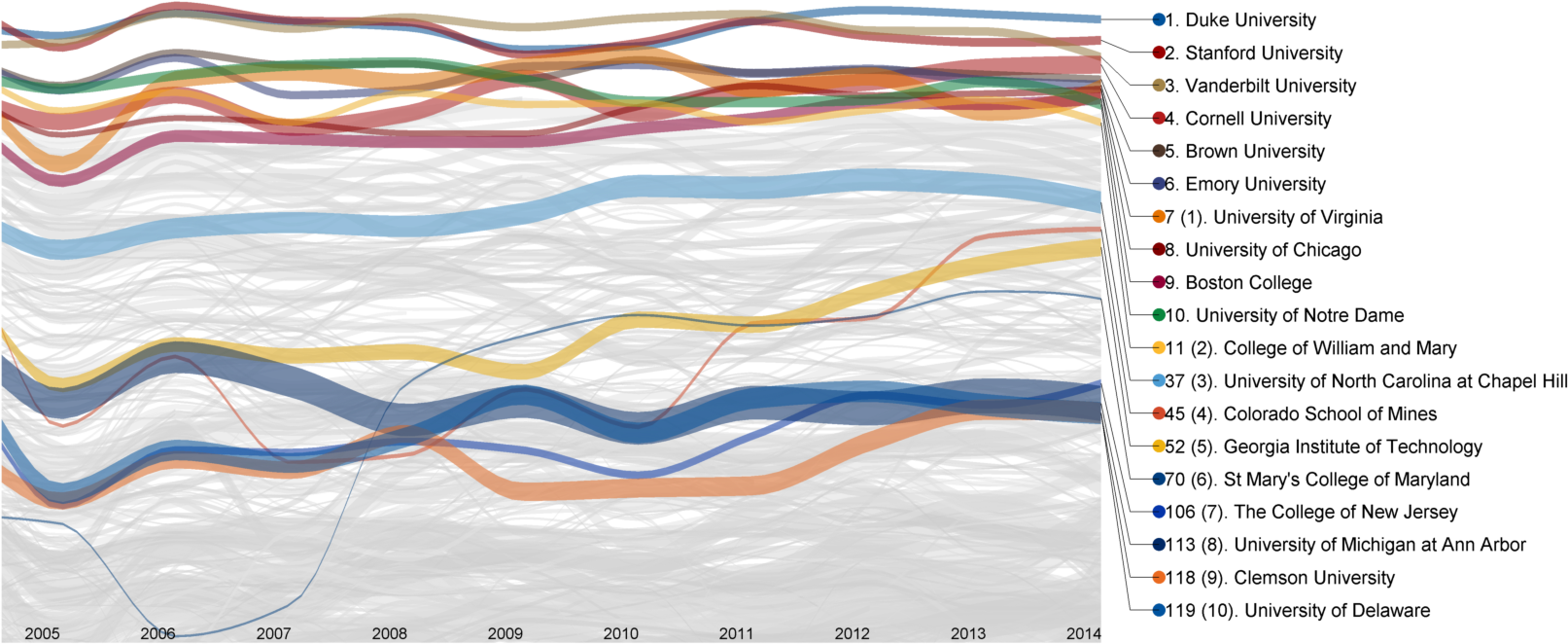
College quality between 2005-2014 for the top 10 private and top 10 public schools as of 2014. The line thickness is proportional to the size of the student population.
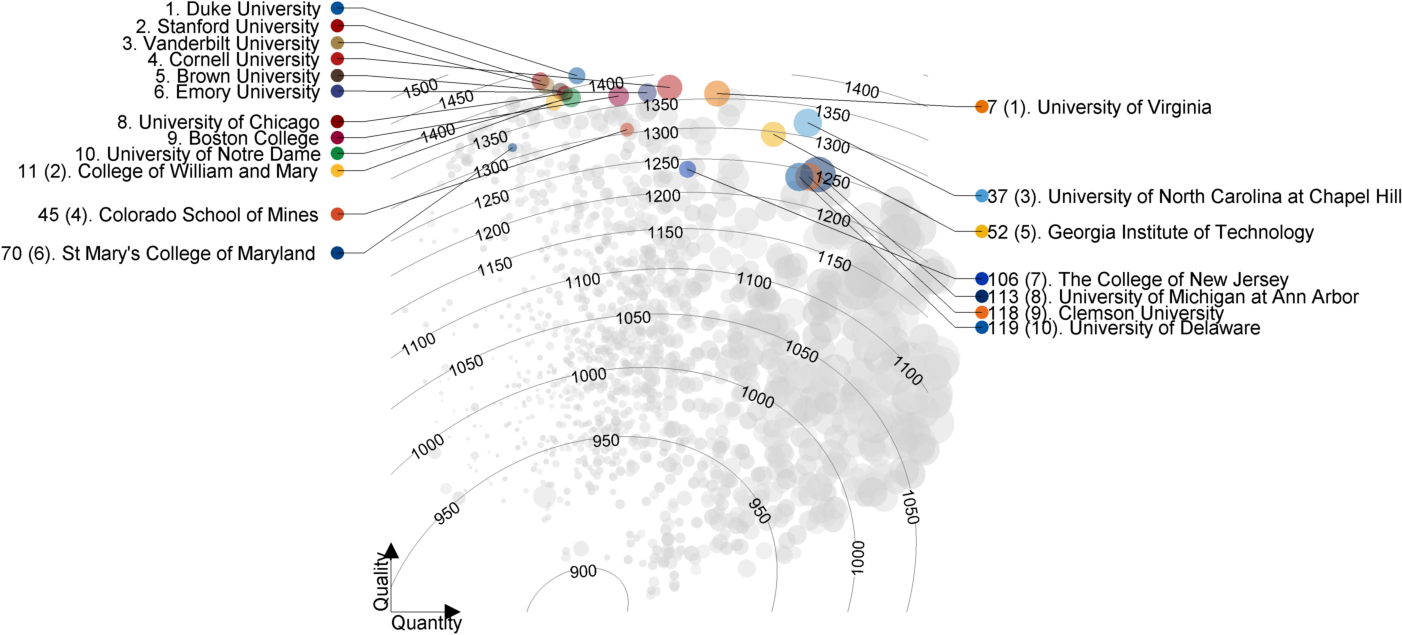
College quality versus quantity for the top 10 private and top 10 public schools in 2014. Circle area is proportional to the size of the student population. Approximate SAT score contour lines are superimposed.
Most of the schools in the top 20 are present in the top 20 in at least one of the published rankings listed earlier. Seven schools—University of Virginia (7), Boston College (9), William and Mary (11), Wesleyan (13), Bucknell University (17), and Santa Clara University (19)—are the newcomers. Of those, the first four schools are reasonably close to being ranked in the top 20 in at least one other ranking, while the latter two are more surprising.
The most conspicuous name is 19th ranked Santa Clara University, a private school of about 5,000 undergraduate students located in Silicon Valley. It is typically ranked in the low 100s (the consensus still places it in the top 10% of all schools) with its best ranking of 64 by Forbes. However, it is impressing the AI and likely disproportionately benefits from a more holistic use of the data instead of using only the typical metrics used to differentiate top schools.
The most conspicuously missing names are the Ivy League schools Harvard (ranked 31st by the AI), Princeton (51), Dartmouth (23) and Columbia (26) along with Caltech (74) and Rice (25). It seems like blasphemy to rank Harvard and Princeton, arguably the most prestigious colleges in the United States, so far down. Caltech at 74 is probably the most jarring of all. However, we take this opportunity to remind you that the AI is not developing a metric strictly of prestige, reputation, the academic caliber of students, or earnings potential of its graduates, but something else that is different, but related.
Duke, Stanford, and Vanderbilt are at the top of the rankings and in any given year any one of them can take the top spot according to the AI. All three schools are often, if not always, ranked in the top 20 in other published rankings. Duke sometimes makes the top five while Stanford does so more often.
Although it goes against our human instincts, not too much weight should be given to the exact ranking of the top schools—relative to the variation in the rest of the field, the differences in quality are small and it’s very tight at the top.
The caveats and more
Throwing things through a black box is often a double-edged sword. You can avoid certain errors and biases that occur in human thinking, but algorithms often come with their own—or at least what we would consider—errors and biases. To an algorithm, data is data, and it’s all fair-game to use to meet some end. What if the neural network believes higher tuition rates, because they are associated with other favorable school characteristics, places a school higher on the dimension that encodes those things? A human would know that higher costs, without commensurate changes in other metrics, should count against a school. Sure, if corresponding quality was not reflected in other metrics, it’s likely the algorithm would mostly ignore the tuition data, but it might not actually lower the resulting quality output. That’s something humans bring to the table with their broad and vast real-world knowledge.
Even more concerning, what if it uses racial demographics to do the same? Unsurprisingly, an algorithm that’s agnostic to what data it is fed has the potential to be politically and socially insensitive. One may think the solution is to just curate what goes into the black box, but there are often proxies for the same information that the algorithm can exploit. This is a commonly cited, controversial hazard of black box machine learning algorithms that should always be kept in mind.
Additionally, these results are based on data aggregated across entire schools. Each student applying to or attending a school has a unique situation. There is much variation in a student population and the programs offered within a school. A single measure or ranking applied to a whole school does not tell you everything you need to know to make the best college decision, but it can provide some valuable context and some level of accountability for the schools themselves.
Of course, there is the axiom that an analysis can only be as good as the data, and while the AI should be relatively robust to sporadic random data errors, systematic errors are another story.
There are many more nuanced and technical caveats for this type of analysis. It is not perfect and the rankings should not be viewed as infallible. But when viewed among other college rankings, its validity is undeniable. It’s not merely a measure of prestige, and it addresses most of the concerns of critics of college rankings, while undoubtedly raising some new ones. However, the results somewhat “feel right.” The renowned “sabermetrician” Bill James was credited with saying, “If you have a metric that never matches up with the eye test, it’s probably wrong. And if it never surprises you, it’s probably useless. But if four out of five times it tells you what you know, and one of out five it surprises you, you might have something.’’ I think we might have something.
Whether you are researching schools to apply to, are curious about your own alma mater, or generally curious, full results can be found in an interactive table, along with other (possibly more useful and less controversial) results that are generated from this type of methodology (such as discovering “hidden” Ivy League schools, value-add metrics, and relatedness of schools).
Footnotes
- We actually train an ensemble of neural networks and average for more reliable results.
- These rankings are as of 2014, the last year of the College Scorecard that has sufficient data.
- Wake Forest University is in the top 20 between the years 2004-2009, but has insufficient data afterwards.
Anywhere we can see the details of the neural network architecture you used? That might help explain some of the results.
Hey, John! We do have more details posted at
https://metametricsinc.com/college-scorecard/
(which is where clicking the “interactive table” link leads) and
https://metametricsinc.com/research-publications/new-school-thought-thoughts-schools-using-neural-networks-enable-novel-higher-education-analytics/
(which is where a link at the end of that page leads). Sorry! We should have made that more obvious. I’m excited that you want to know more!
Love it
LIBERATED FROM DEBT, NOW PROPERTIES OWNER WITH THE HELP OF PROSPER LOAN: [email protected]