- A Next-Generation Open Source Courseware Platform Collaboration
- A Courseware Platform for Expressing Pedagogical Intent
- There’s a Layer in Between Learning Content and Learning Analytics
This post is the third in a series about the collaboration on a new courseware platform between Carnegie Mellon University’s Open Learning Initiative (OLI) and Arizona State University’s Center for Education Through eXploration (ETX). (The web version of this post has a clickable table of contents up at the top.) I’ll be writing about the platform periodically on a variety of topics ranging from nuts-and-bolts questions like what features it will have by when all the way to very broad and deep topics like architecture, interoperability standards, and hoped-for impacts on the educational ecosystem. As a reminder, I’ll also be holding a Blursday Social webinar with OLI’s Norman Bier and ETX’s Ariel Anbar on this Thursday, 2/4 at 4 PM ET.
Today I want to review a fundamental aspect of the collaboration that I discussed in my previous post in this series from a slightly different angle. Not too long ago, I had a conversation about this angle with a new friend. After we had waded into it for a while, she said to me, “Everybody wants to talk about content and learning analytics. You’re saying that there’s a layer in between.”
Exactly. She expressed it perfectly.
And yet, two aspects about that moment surprised me.
First, even though I have been writing about this idea almost since I started this blog in 2005 and have involved in the design of multiple EdTech systems that rely on this principle, I had never thought about it in quite the way she had put it before she said it. Second, I don’t think she had either. For context, my new friend is a PhD candidate in experimental psychology who is only weeks away from defending her dissertation at Carnegie Mellon University. She has a history in EdTech that is as long as mine. Furthermore, she had to be working with this concept directly and intimately, given the subject of her dissertation. And yet, her formulation of this idea also seemed novel to her as she expressed it to me in that moment.
If I am still finding new ways to wrap my head around this concept, and she is too, then chances are good, Dear Reader, that previous blog posts I’ve written about the topic have failed to fully communicate the idea to you as well. So I’m going to take another go at it in this post. First I’m going to talk about what, generally speaking, we mean by “in between” and then about why it’s important for us to understand the layer that’s “in between” learning content and learning analytics.
Meaning is the meat of the sandwich
Imagine I handed you a piece of paper with “8429971043” written on it. Take a moment and try to imagine contexts in which that act would make sense to you. What might that number mean? Why would I be giving it to you? Sketch out a few stories in your head.
Now instead, imagine I handed you a piece of paper with “(842) 997-1043” written on it. What stories are you writing in your head now? Did I give it to you printed on a little piece of cardboard at the beginning of a business meeting? Scrawled on a napkin in a bar?
Now go back and reread those last two questions. Notice how much insight you were able to extract from the context embedded in the questions once you recognized that string of numbers as a phone number, as opposed to just a string of ten digits.
Without the meaning of the number, you had the content, and you were trying to perform your analytics, but you were severely limited. The enabling layer in the middle is the idea of a phone number. Given just a little bit of punctuation, your brain transformed a random string of numbers into a thing in the world that you can do something with. It also enabled you to extract new information value out of other contextual information, like the kind of paper the number was written on or the location in which the paper was exchanged.
There was a moment in the history of software when computing machines were given this layer in the middle for phone numbers. On one day, a phone number in an email wasn’t clickable (or tappable). The next day, it was. Clicking on it now offers you several predictable options. Would you like to associate this number with a person in your address book? Would you like to dial it now?
Software developers deal with this “in between” layer all the time. They call it an “information model.” Consider, for example, the address book which stores the phone number that you clicked on. It has an information model that knows that phone numbers can belong to people. It knows that people can also have email addresses, physical addresses, company affiliations, and other things. Emphasis is on things. John Smith isn’t just a string of letters; it’s the name of a person. (842) 992-1043 isn’t just a string of numbers, spaces, and punctuation marks; it’s John Smith’s phone number.
Information models represent meaning, including relationships between things (such as the relationship between John Smith and his phone number). Software architects work very hard to replicate the relevant ways in which we parse and store meaning in our heads to perform tasks that are relevant to the software being built. Suppose John Smith lives in Europe, where phone numbers have different numbers of digits. Suppose he writes his phone number as 842.992.1043. Suppose he has multiple phone numbers which he uses for different purposes in different locations. An information model has to capture all of these nuances. It’s hard work, but it’s a well understood process. Software developers do it all the time. They are constantly mapping bits of the human world into their software.
For some reason, humans seem to struggle when thinking about how to map learning and teaching in this way. Even experienced and formally trained humans who think about it all the time struggle with it. We could chalk that up to how incredibly complex the human mind is. And there’s something to that. Learning is comprised of an incredibly complicated and varied array of processes. I’m going to write about that problem and its implications for, say, adaptive learning in a future post. But I don’t think that’s the whole story because even basic building blocks seem hard for us to wrap our heads around.
Hard, but not impossible. Let’s give it a try.
The pedagogical meaning in the middle
Imagine you’re in a literature class studying The Odyssey. Your professor asks you the name of Odysseus’ dog. You may have one of two common reactions to this question. One is to try to come up with a thoughtful answer. The other is to roll your eyes in frustration. The reaction you have is related to the meaning you believe is attached to the name of Odysseus’ dog. If the name has no meaning—if it’s the Greek equivalent of “Spot” or “Rex”—then you might roll your eyes because you don’t think this question is has value relative to its purpose, which is to help you understand The Odyssey. The instructor’s question is a thing that is supposed to have a use. Specifically, it is supposed to help you learn—or show what you have already learned—about the literature. You expect it to fulfill one or both of those functions. You expect that the question, answer, and purpose for asking are all related to each other and to The Odyssey. This is the information model in your head that drives your interactions with your instructor. When your instructor asks you a question that doesn’t lead to an answer that helps you better understand the literature, then you get frustrated. It’s a little like being asked to memorize a phone number without knowing whose phone number it is or why you need to know it.
When we are designing a lesson, either in software or in an old-fashioned, human-to-human class, we are (consciously or unconsciously) drawing on this information model.
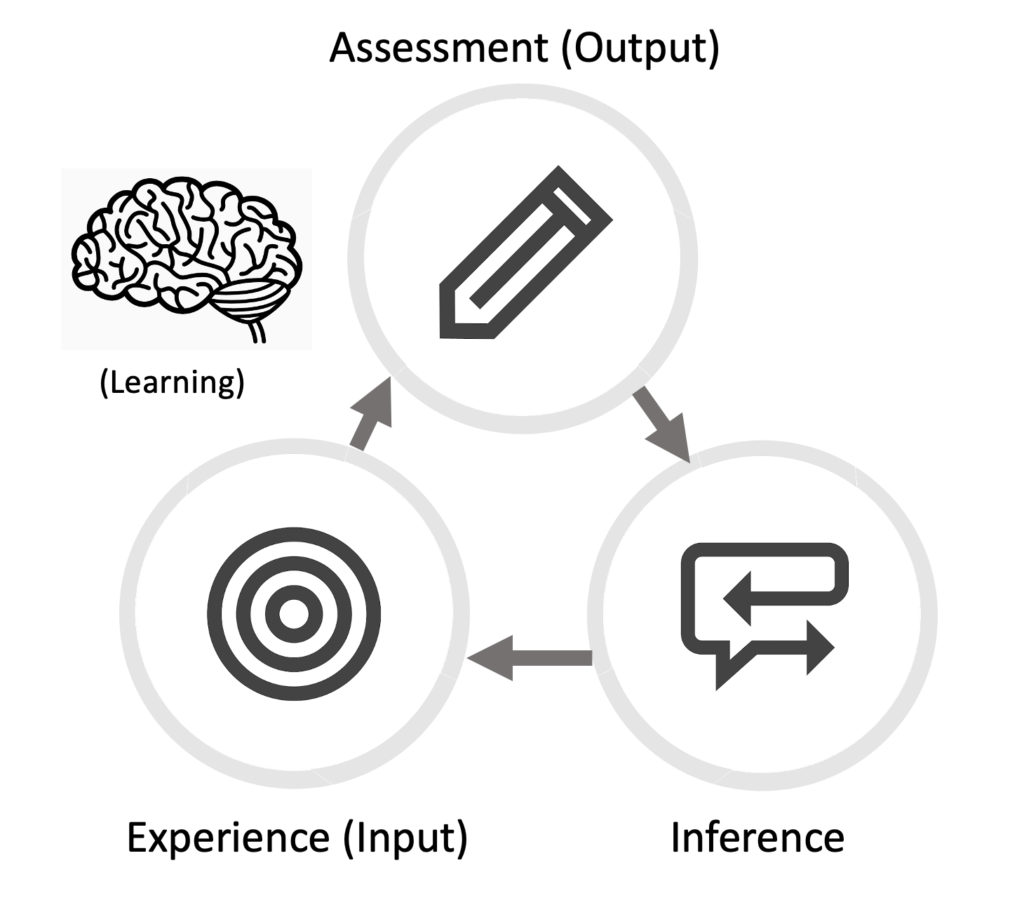
Let’s see how this works with some more interesting questions about Odysseus’ dog. Suppose your instructor asked you, “Why does the author write about the dog at all? What is the function of the dog in the story?” That feels like meaningful question. If you’ve read The Odyssey, you may remember that the dog only appears in one scene and dies almost immediately. It’s not like the dog (whose name is “Argos,” by the way) is a major character in the story. It shows up exactly once, at a moment in the story that is very dramatic for reasons that seem completely unrelated to the dog dying. What’s that about?
Now let’s try a similar mental exercise to the one we tried with the phone number. Imagine your instructor asking that question in different contexts. What would it mean if she gave you the question to think about before you read the passage? How would the meaning of the question—or maybe more more precisely, how would the purpose of the question change if your instructor asked that question in class discussion after you had already read the passage? How would it function differently if the question came as an essay exam question after the class discussion?
In context, we can answer these questions fairly easily. The instructor is asking the student a question about a work of literature that is intended to stimulate or test the student’s understanding of some specific aspect of the literature. We can judge the nuances regarding stimulating versus testing understanding based on the context. That is our tacit information model. And yet, both educators and software developers, and even experts who study learning, can struggle to hold onto the model in the general case.
This is an important problem to solve if we want to improve education in general and EdTech in particular.
Making tacit educational knowledge explicit
As humans, we have an enormous amount of experience with learning through questions or challenges. Why is there a dog in that scene? How do I calculate how steep a hill is? Why are my scrambled eggs so runny? What is the guitar chord in that song I love? What will happen if I lick a frozen flag pole? We try to answer these questions. The emphasis is on try. We learn by doing (even if the thing we are doing is in our heads, like imagining what might happen if we lick that frozen flag pole). If we don’t get the answer we’re looking for the first time, we may try again or try something else. These are goal-directed learning feedback loops. As animals, we understand these loops instinctively. It’s an essential part of what makes us human. One translation of the sapiens part of homo sapiens is “one who knows.” This knack for knowing is how humans survive as a species. For example, I want to believe that most people who lick frozen flagpoles once don’t do it again. On the other hand, people who are serious about making good scrambled eggs may experiment repeatedly with pan heat, scrambling technique, and other elements. Each of these, in turn, produces a question that leads us to construct a goal-directed learning feedback loop. “What if the eggs are runny because I’m not getting them scrambled evenly enough?” And so we try again.
Teaching is the craft of creating, optimizing, and sequencing goal-directed feedback loops that help learners learn. But because these loops are so intuitively available to us, we often don’t think explicitly about what we’re doing. Many of us don’t have a clear mental model for a fundamental task that we perform all the time. Even those of us who do can struggle to keep that model in our conscious minds and continue to refine it. It’s hard to refine your model if you can’t keep it front-of-mind as you’re testing it. And it’s really hard to translate it into a software information model.
In my personal view, one of the most exciting goals of the OLI/ETX collaboration is the opportunity to work on this challenge of making a broad swathe of our tacit knowledge about educational processes explicit. On the software architecture side, the exercise of translating the very different learning experiences supported by OLI and Smart Sparrow into a common information model describing goal-directed learning feedback loops helps us generalize. I believe we are searching for the language of educational DNA.
Let’s take that analogy seriously. In actual DNA, all of life in its infinite variety and complexity is encoded using just four letters in strands of DNA. I believe we can describe the basic, universal building blocks that encode learning in all its infinite variety and complexity. Of course, knowing those building blocks does not unlock all the secrets of life or learning by itself. But it’s a pretty big step in the right direction. An ambitious but achievable intermediate goal would be to be able to create and test any style of effective courseware design, including adaptive learning designs, using a single information design and architecture.
The more important aspect of this aspiration is on the human side. If we can create a system that helps both educators and students translate the teaching and learning knowledge they apply instinctively into an explicit model, see the benefits that doing so gives them in terms of extracting more meaning out of educational contexts, and practice translating their tacit knowledge about teaching learning into explicit knowledge, that would be transformative. We would become better teachers and learners because we would be translating teaching and learning from arts to crafts and, when possible, to science.
To sum up, I believe the software that is emerging from the collaboration between OLI and ETX can help educators and students become more effective at learning about teaching and learning while simultaneously creating an architecture that can implement almost any style of courseware on the market today and some that aren’t on the market yet. It can accomplish both of these goals by baking a model for the basic building block of teaching and learning—the goal-directed feedback loop—into every aspect of the platform, from the user experience to the deep architecture. This, in turn, will enable other capabilities that I will write about in future posts.
If you want to talk about this (or any other aspect of the project), come to the Blursday Social webinar with OLI’s Norman Bier and ETX’s Ariel Anbar on this Thursday, 2/4 at 4 PM ET.