Last week Harvard and MIT released de-identified data from their edX-based MOOCs. Rather than just produce a summary report, the intent of this release was to open up the data and share it publicly. While it is good to see this approach to Open Data, unfortunately the data set is of limited value, and it actually illustrates a key problem with analytics in higher ed. From MIT News description:
A research team from Harvard University and MIT has released its third and final promised deliverable — the de-identified learning data — relating to an initial study of online learning based on each institution’s first-year courses on the edX platform.
Specifically, the dataset contains the original learning data from the 16 HarvardX and MITx courses offered in 2012-13 that formed the basis of the first HarvardX and MITx working papers (released in January) and underpin a suite of powerful open-source interactive visualization tools (released in February).
At first I was eager to explore the data, but I am not sure how much useful insight is possible due to how the data was collected. The data is structured with one student per row for each course they took (taking multiple courses would lead to multiple rows of data). The data columns (pulled from the Person Course Documentation file) are shown below:
- course_id: ID for the course
- userid_DI: de-identified unique identifier of student
- registered: 0/1 with 1 = registered for this course
- viewed: 0/1 with 1 = anyone who accessed the ‘courseware’ tab
- explored: 0/1 with 1 = anyone who accessed at least half of the chapters in the courseware
- certified: 0/1 with 1 = anyone who earned a certificate
- final_cc_name_DI: de-identified geographic information
- LoE: user-provided highest level of education completed
- YoB: year of birth
- gender: self-explanatory
- grade: final grade in course
- start_time_DI: date of course registration
- last_event_DI: date of last interaction with course
- nevents: number of interactions with the course
- ndays_act: number of unique days student interacted with course
- nplay_video: number of play video events
- nchapters: number of courseware chapters with which the student interacted
- nforum_posts: number of posts to the discussion forum
- roles: identifies staff and instructors
The problem is that this data only tells us very shallow usage patterns aggregated over the entire course – did they look at courseware, how many video views, how many forum posts, final grade, etc. I have described several times how open courses such as MOOCs have different student patterns, since not all students have the same goals for taking the course.
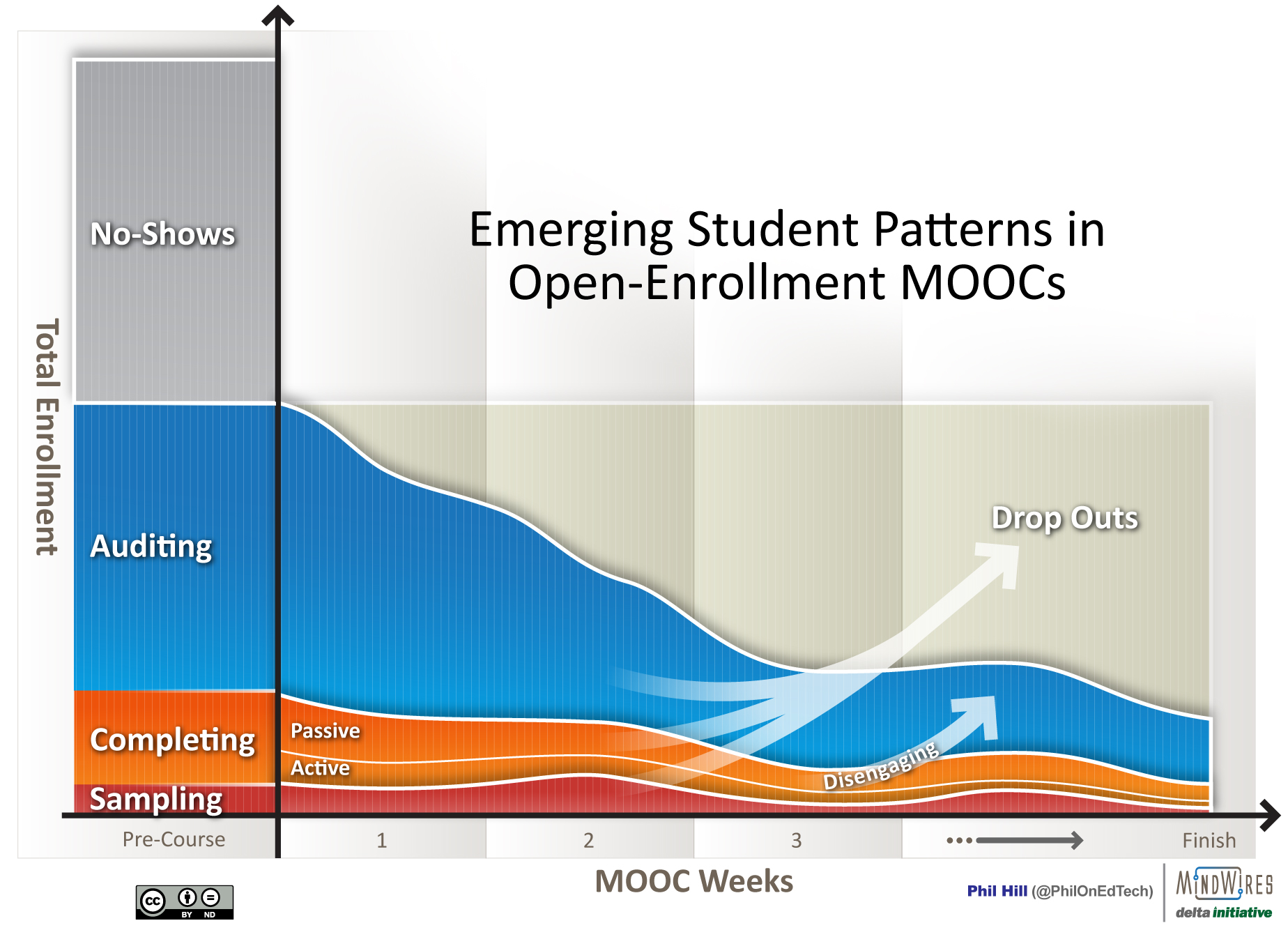
The Harvard and MIT data ignores student goals or any information giving a clue on whether students desired to complete the course, get a good grade, get a certificate, or just sample some material. Without this information on student goals, the actual aggregate behavior is missing context. We don’t know if a certain student intended to just audit a course, sample it, or attempt to complete it. We don’t know if students started the course intended to complete but became frustrated and dropped down to just auditing or even dropped out.
Beyond data aggregated over the entire course, the Harvard and MIT edX data provides no insight into learner patterns of behavior over time. Did the discussion forum posts increase or decrease over time, did video access change over time, etc? We don’t know. There is some insight we could obtain by looking at the last transaction event and number of chapters accessed, but the insight would be limited. But learner patterns of behavior can provide real insights, and it is here where the University of Phoenix (UoP) could teach Harvard and MIT some lessons on analytics.
Also last week, the Apollo Group (parent of UoP) CIO Mike Sajor gave an interview to Campus Technology, and he discussed their new learning platform (also see my previous post on the subject). In one segment Sajor explained how the analytics are being used.
Sajor: Another aspect: We leverage the platform to collect a vast amount of data about students as they traverse their learning journey. We know what they’re doing, when they’re doing it, how long it takes, anything they do along the journey that might not have been the right choice. We collect that data … and use it to create some set of information about student behaviors. We generate insight; and insight tells us an interesting fact about a student or even a cohort of students. Then we use that insight to create an intervention that will change the probability of the student outcome.
CT: Give an example of how that might work.
Sajor: You’re a student and you’re going along and submitting assignments, doing reading, doing all those things one would normally do in the course of a class. Assignments are generally due in your class Sunday night. In the first few weeks you turn your assignments in on Friday. And suddenly, you turn in an assignment on Saturday evening, and the next week you turn one in mid-day Sunday. Well, we’re going to notice that in our analytics. We’ll pick that up and say, “Wait a second. Sally Student now has perturbation in her behavior. She was exhibiting a behavioral pattern over time since she started as a student. Now her pattern has shifted.” That becomes an insight. What we do at that point is flag the faculty member or an academic adviser or enrollment adviser to contact Sally using her preferred mode — e-mail, phone call. And we’ll ask, “Hey Sally, we noticed you’re turning in your assignments a little bit later than you normally did. Is there anything we can do to help you?” You’d be amazed at the answers we get, like, “My childcare on Thursday and Friday night fell apart.” That gives us an opportunity to intervene. We can say, “You’re in Spokane. We know some childcare providers. We can’t recommend anybody; but we can give you a list that might help you.”
UoP recognizes the value of learner behavior patterns, which can only be learned by viewing data patterns over time. The student’s behavior in a course is a long-running transaction, with data sets organized around the learner.
In edX, by contrast, the data appears to be organized a series of log files organized around server usage. Such an organization allows aggregate data usage over a course, but it makes it extremely difficult to actually follow a student over time and glean any meaningful information.
The MIT News article called out why this richer data set is so important:
Harvard’s Andrew Ho, Chuang’s co-lead, adds that the release of the data fulfills an intention — namely, to share best practices to improve teaching and learning both on campus and online — that was made with the launch of edX by Harvard and MIT in May 2012.
If you want to “share best practices to improve teaching and learning”, then you need data organized around the learner, with transactions captured over time – not just in aggregate. What we have now is an honest start, but a very limited data set.
I certainly wouldn’t advocate Harvard and MIT becoming the University of Phoenix, but in terms of useful learner analytics, they could learn quite a bit. I applaud Harvard and MIT for their openness, but I hope they develop better approaches to analytics and learn from others.
Note: The Harvard and MIT edX is de-identified to fit within FERPA requirements, but after reading their process, it does not appear that the learner patterns were removed due to privacy concerns.
Update: Based on private feedback, I should clarify that I have not validated that the UoP analytics claims actually work in practice. I am giving them credit for at least understanding the importance of learner-centered, behavior-based data to improve teaching and learning, but I do not know what has been fully implemented. If I find out more, I’ll share in a separate post.
On this point, there is an angle of ‘what University of Phoenix could learn from Harvard and MIT on analytics’ regarding Open Data and the ability to see real results.
Non-aggregated microdata (or a “person-click” dataset, see http://blogs.edweek.org/edweek/edtechresearcher/2013/06/the_person-click_dataset.html ) are much harder (impossible?) to de-identify. So you are being unfair in comparing this public release of data with internal data analytic efforts.
Ewout – you have a point about the difference between public release of data and internal data; however, that doesn’t eliminate the opportunity to learn from others. Fair, in my mind, has nothing to do with it.
On the non-aggregated microdata, privacy / de-identification might be a reason to not attempt to release the full dataset, but the bigger issue is _whether HarvardX and MITx are even looking at learner-centered, time-based data_. Have you seen any evidence from them or edX of useful data of this type being analyzed and released in aggregate form? I have not, and I strongly suspect there is a reason based on the data available.
Stanford has shown that it is possible to capture and learn from this data within a MOOC – see http://www.stanford.edu/~cpiech/bio/papers/deconstructingDisengagement.pdf. That is based on analysis from 3 Coursera courses I believe.