In my recent IMS update post, I wrote,
[T]he nature and challenges of interoperability our sector will be facing in the next decade are fundamentally different from the ones that we faced in the last one. Up until now, we have primarily been concerned with synchronizing administration-related bits across applications. Which people are in this class? Are they students or instructors? What grades did they get on which assignments? And how much does each assignment count toward the final course grade? These challenges are hard in all the ways that are familiar to anyone who works on any sort of generic data interoperability questions.
But the next decade is is going to be about data interoperability as it pertains to insight. Data scientists think this is still familiar territory and are excited because it keeps them at the frontier of their own profession. But this will not be generic data science, for several reasons.
I then asserted the following positions:
- Because learning processes are not directly observable, blindly running machine learning algorithms against the click streams in our learning platforms will probably not teach us much about learning.
- On the other hand, if our analytics are theory-driven, i.e., if we start with some empirically grounded hypotheses about learning processes and design our analytics to search for data that either support or disprove those hypotheses, then we might actually get somewhere.
- Because learning analytics expressions written in the IMS Caliper standard can be readily translated into plain English, Caliper could form a basis for expressing educational hypotheses and translating them into interoperable tools for testing those hypotheses across the boundaries of tech tools and platforms.
- The kind of Caliper-mediated conversation I imagined among learning scientists, practicing educators, data scientists, learning system designers, and others, is relevant to a term coined and still used heavily at Carnegie Mellon University—”learning engineering.”
In this post, I’m going to explore the last two points in more detail.
What the heck is “learning engineering”?
The term “learning engineering” was first used by Nobel laureate and Carnegie Mellon University polymath Herbert Simon in 1966. It has been around for quite a while. But it is a term whose time as finally has come and, as such, we are seeing the usual academic turf wars over its meaning and value. On the one hand, some folks love it, embrace it, and want to apply it liberally. IEEE has an entire group devoted to defining it. As is always the case, some of this sort of enthusiasm is thoughtful, and some of it is less so. At its worst, there is a tendency for people to get tangled up in the term because it provides a certain je ne sais quoi they’ve been yearning for to describe the aspects of their jobs that they really want to be doing as change agents rather than the mundane tasks that they keep being dragged back into doing, much like the way some folks are wrapping “innovation” and “design” around themselves like a warm blanket. It’s perfectly understandable, and I think it attaches to something real in many cases, but it’s hard to say exactly what that is. And, of course, where there are enthusiasts in academia, there are critics. Again, some thoughtful, while others…less so. (Note my comment in the thread on that particularly egregious column.)
If you want to get a clear sense of the range of possible meanings of “learning engineering” as used by people who actually think about it deeply, one good place to start would be Learning Engineering for Online Education: Theoretical Contexts and Design-Based Examples edited by Chris Dede, John Richards, and Bror Saxberg. (I am still working on getting half a day’s worth of Carnegie Mellon University video presentations on their own learning engineering work ready for posting on the web. I promise it is coming.) There are a lot of great take-aways from that anthology, one of which is that even the people who think hard about the term and work together to put together something like a coherent tome on the subject don’t fully agree on what the term means.
And that’s really OK. Let’s just set a few boundary conditions. On the one hand, learning engineering isn’t an all-encompassing discipline and methodology that is going to make all previous roles, disciplines, and methodologies obsolete. If you are an instructional designer, or a learning designer, or a user experience designer; if you practice design thinking, or ADDIE; be not afraid. On the other hand, learning engineering is not creeping Stalinism either. Think about learning engineering, writ large, as applying data and cognitive sciences to help bring about desired learning outcomes, usually within the context of a team of colleagues with different skills all working together. That’s still pretty vague, but it’s specific enough for the current cultural moment.
Forget about your stereotypes of engineers and their practices. Do you believe there is a place for applied science in our efforts to improve the ways in which we design and deliver our courses, or try to understand and serve our students needs and goals? If so, what would such an applied science look like? What would a person applying the science need to know? What would their role be? How would they work with other educators who have complementary expertise?
That is the possibility space that learning engineering inhabits.
Applied science as a design exercise
One of the reasons that people have trouble wrapping their heads around the notion of learning engineering is that it was conceived of by very unusual mind. Some of the critiques I’ve seen online of the term position “learning engineering” in opposition to “learning design.” But as Phil Long points out in his essay in the aforementioned anthology, Herb Simon both coined the term “learning engineering” and is essentially the grandfather of design thinking:
Design science was introduced by Buckminster Fuller in 1963, but it was Herbert Simon who is most closely associated with it and has established how we think of it today. “The Sciences of the Artificial” (Simon, 1967) distinguished the artificial, or practical sciences, from the natural sciences. Simon described design as an ill-structured problem, much like the learning environment, which involves man-made responses to the world. Design science is influenced by the limitations of human cognition unlike mathematical models. Human decision-making is further constrained by practical attributes of limited time and available information. This bounded rationality makes us prone to seek adequate as opposed to optimal solutions to problems. That is, we engage in satisficing not optimizing. Design is central to the artificial sciences: ‘Everyone designs who devises courses of action aimed at changing existing situations into desired ones.’ Natural sciences are concerned with understanding what is; design science instead asks about what should be. this distinction separates the study of the science of learning from the design of learning. Learning scientists are interested in how humans learn. Learning engineers are part of team focused on how students ought to learn.”
Phil Long, “The Role of the Learning Engineer”
Phil points out two important dichotomies in Simon’s thinking. The first one: is vs. ought. Natural science is about what is, while design science is about what you would like to exist. What you want to bring into being. The second dichotomy is about well structured vs. poorly structured. For Simon, “design” is a set of activities one undertakes to solve a poorly structured problem. To need or want is human, and to be human is to be messy. Understanding a human need is about understanding a messy problem. Understanding how different humans with different backgrounds and different cognitive and non-cognitive abilities learn, given a wide range of contextual variables like the teaching strategies being employed, the personal relationships between students and teacher, what else is going on in the students’ lives at the time, whether different students are coming to class well fed and well slept, and so on, is pretty much the definition of a poorly structured problem. So as far as Herb Simon is concerned, education is a design problem by definition, whether or not you choose to use the word “engineer.”
In the next section of his article, Phil then makes a fascinating connection between the evolution of design thinking, which emerged out design science, and learning engineering. The key is in identifying the central social activity that defines design thinking:
Design thinking represents those processes that designers use to create new designs, possible approaches to problem solutions spaces where none existed before. A problem-solving method has been derived from this and applied to human social interactions iteratively taking the designer and/or co-design participants from inspiration to ideation and then to implementation. The designer and design team may have a mental model of the solution to a proposed problem, but it is essential to externalize this representation in terms of a sketch a description of a learning design sequence, or by actual prototyping of the activities which the learner is asked to engage. [Emphasis added.] All involved can see the attributes of the proposed design solution that were not apparent in the conceptualization of it. this process of externalizing and prototyping design solutions allows it to be situated in larger and different contexts, what Donald Schon called reframing the design, situating it in contexts other than originally considered.
Phil Long, “The Role of the Learning Engineer”
So the essential feature that Phil is calling out in design thinking is putting the idea out into the world so that everybody can see it, respond to it, and talk about it together. Now watch where he takes this:
As learning environments are intentionally designed in digital contexts, the opportunity to instrument the learning environment emerges. Learners benefit in terms of feedback or suggested possible actions. Evaluators can assess how the course performed on a number of dimensions. The faculty and others in the learning-design team can get data through the instrumented learning behaviors, which may provide insight into how the design is working, for whom it is working, and in what context.
Phil Long, “The Role of the Learning Engineer”
Rather than a sketch, a wireframe, or a prototype, a learning engineer makes the graph, the dashboard, or the visualization into the externalization. For Herb Simon, as for Phil Long, these design artifacts serve the same purpose. They’re the same thing, basically.
If you’re not a data person, this might be hard to grasp. (I’m not a data person. This is hard for me to grasp sometimes.) How can you take numbers in a table and turn them into a meaningful artifact that a group of people can look at together, discuss, make sense of, debate, and learn from? What might that even look like?
Well, it might look something like this, for example:
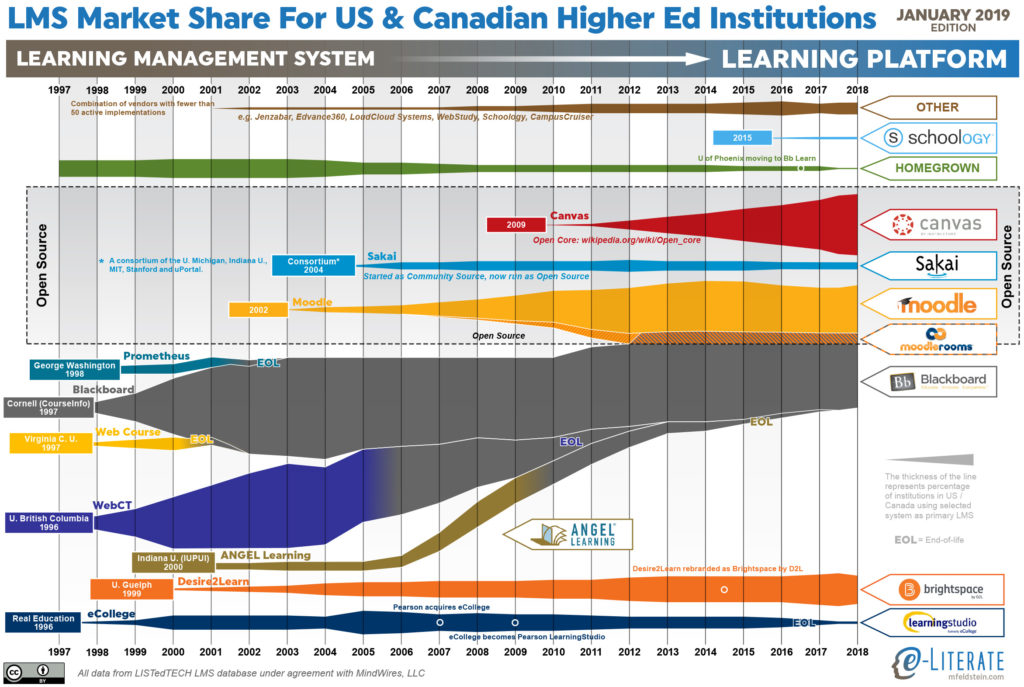
Phil Hill has a graduate degree in engineering. Not learning engineering. Electrical. (Also, he’s not a Stalinist.)
By the way, when we externalize and share data with a student about her learning processes in a form that is designed to provoke thought and discussion, we have a particular term of art for that in education. It’s called “formative assessment.” If we do it in a way such that the student always has access to such externalizations, which are continually updating based on the student’s actions, we call that “continuous formative assessment.” When executed well, there is evidence that it can be an effective educational practice.
Caliper statements as learning engineering artifacts
So here’s where we’ve arrived at this point in the post:
- Design is a process by which we tackle ill-defined problems of meeting human needs and wants, such as needing or wanting to learn something.
- Engineering is a word that we’re not going to worry about defining precisely for now, but it relates to applying science to a design problem, and therefore often involves the measurement and numbers.
- One important innovation in design methodology is the creation of external artifacts early in the design process so that various stakeholders with different sorts of experience and expertise can provide feedback in a social context. In other words, create something that makes the idea more “real” and therefore easier to discuss.
- Learning engineering includes the skills of creation and manipulation of design artifacts that require more technical expertise, including expertise in data and software engineering.
The twist with Caliper is that, rather than using visualizations and dashboards as the externalization, we can use human language. This was the original idea of behind the Semantic Web, which is still brilliant in concept, even if the original implementation was flawed. Let’s review that basic idea as implemented in Caliper:
- You can express statements about the world (or the world-wide web) in three-word sentences of the form [subject] [verb] [direct object] e.g., [student A] [correctly answers] .
- Because English grammar works the way it does, you can string these sentences together to form inferences, e.g., [tests knowledge of] [multiplying fractions]; therefore, [student A] [correctly answers] [a question about multiplying fractions].
- We can define mandatory and optional details of every noun and verb e.g., it might be mandatory to know that question 13 was a multiple choice question, but it might be optional to include the actual text of the question, the correct answer, and the distractors.
That’s it. Three-word sentences, which work the way they do in English grammar, and definitions of the “words.”
A learning engineer could use Caliper paragraphs as a design artifact to facilitate conversations about refining the standard, the products involved, and the experimental design. I’ll share a modified version of an example I recently shared with an IMS engineer to illustrate this same point.
Suppose you are interested in helping students become better at reflective writing. You want to do this by providing them with continuous formative assessment, i.e., in addition to the feedback that you give them as an instructor, you want to provide them an externalization of the language in their reflective writing assignments. You want to use textual analysis to help the students look at their own writing through a new lens, find the spots where they are really doing serious thought work, and also the spots where maybe they could think a little harder.
But you have to solve a few problems in order to do give this affordance to your students. First, you have to develop the natural language analysis tool that can detect cues in the students’ writing that indicate self-reflection (or not). That’s hard enough, but the research is being conducted and progress is being made. The second problem is that you are designing a new experiment to test your latest iteration and need some sort of summative measure to test against. So maybe you design a randomized controlled trial where half the students in the class use the new feedback tool, half don’t, and all get the same human-graded final reflective writing assignment. You compare the results.
This is an example of theory-driven learning analytics. Your theory is that student reflection improves when students become more aware of certain types of reflective language in their journaling. You think you can train a textual analysis algorithm to reliably distinguish—externalize—the kind of language that you want students to be more aware of in their writing and point it out to them. You want to test that by giving students such a tool and see if their reflective writing does, in fact, improve. Either students’ reflective writing will improve under the test condition, which will provide supporting evidence for the theory, or it won’t, which at the very least will not support the theory and might provide evidence that tends to disprove the theory, depending on the specifics. There are data science and machine learning being employed here, but they are being employed more selectively than just shotgunning an algorithm at a data set and expecting it to come up with novel insights about the mysteries of human cognition.
Constructing theory-driven learning analytics of the sort described here is challenging enough to do in a unified system that is designed for the experiment. But now we get to the problem for which we will need the help of IMS over the next decade, which is that the various activities we need to monitor for this work often happen in different applications. Each writing assignment is in response to a reading. So the first thing you might want to do, at least for the experiment if not in the production application, is to control for students who do the reading. If they aren’t doing the reading, then their reflective writing on that reading isn’t going to tell you much. Let’s say the reading happens to take place in an ebook app. But their writing takes place in a separate notebook app. Maybe it’s whatever notebook app they normally use—Evernote, One Note, etc. Ideally, you would want them to journal in whatever they normally use for that sort of activity. And if it’s reflective writing for their own growth, it should be an app that they own and that will travel with them after they leave the class and the institution. On the other hand, the final writing assignment needs to be submittable, gradable, and maybe markable. So maybe it gets submitted through an LMS, or maybe through a specialized tool like Turnitin.
This is an interoperability problem. But it’s a special one, because the semantics have to be preserved through all of these connections in order for (a) the researchers to conduct the study, and then (b) the formative assessment tool to have real value to the students. The people who normally write Caliper metric profiles—the technical definitions of the nouns in Caliper—would have no idea about any of this on their own. Nor would the application developers. Both groups would need to have a conversation with the researchers in order to get the clarity they need in order to define the profiles for this purpose.
The language of Caliper could help with this if a person with the right role and expertise were facilitating the conversation. That person would start by eliciting a set of three-word sentences from the researchers. What do you need to know? The answers might include statements like the following:
- Student A reads text 1
- Student A writes text alpha
- Text alpha is a learning reflection of text 1
- Student A reads text 2
- Text 2 is a learning reflection of texts 1 and 2
- Etc.
The person asking the questions of the researcher and the feature designer—let’s call that person the learning engineer—would then ask questions about the meanings and details of the words, such as the following:
- In what system or systems is the reading activity happening?
- Do you need to know if the student started the reading? Finished it? Anything finer grained than that?
- What do you need to know about the student’s writing in order to perform your textual analysis? What data and metadata do you need? And how long a writing sample do you need to elicit in order to perform the kind of textual analysis you intend and get worthwhile results back?
- What do you mean when you say that text 2 is a reflection of both text 1 and 2, and how would you make that determination?
At some point, the data scientist and software systems engineers would join in the conversation and different concerns would start to come up, such as the following:
- Right now, I have no way of associating Student A in the note-taking system with Student A in the reading system.
- To do the analysis you want, you need the full text of the reflection. That’s not currently in the spec, and it has performance implications. We should discuss this.
- The student data privacy implications are very different for an IRB-approved research study, an individual student dashboard, and an instructor- or administrator-facing dashboard. Who owns these privacy concerns and how do we expect them to be handled?
Notice that the Caliper language has become the externalization that we manipulate socially in the design exercise. There are two aspects of Caliper that make this work: (1) the three-word sentences are linguistically generative, i.e., they can express new ideas that have never been expressed before, and (2) every human-readable expression directly maps to a machine-readable expression. These two properties together enable rich conversations among very different kinds of stakeholders to map out theory-driven analytics and the interoperability requirements that they entail.
This is the kind of conversation by which Caliper can evolve into a standard that leads to useful insights and tools for improving learning impact. And in the early days, it will likely happen one use case at a time. Over time, the working group would learn from having enough of these conversations that design patterns would emerge, both for writing new portions of the specification itself and for the process by which the specification is modified and extended.
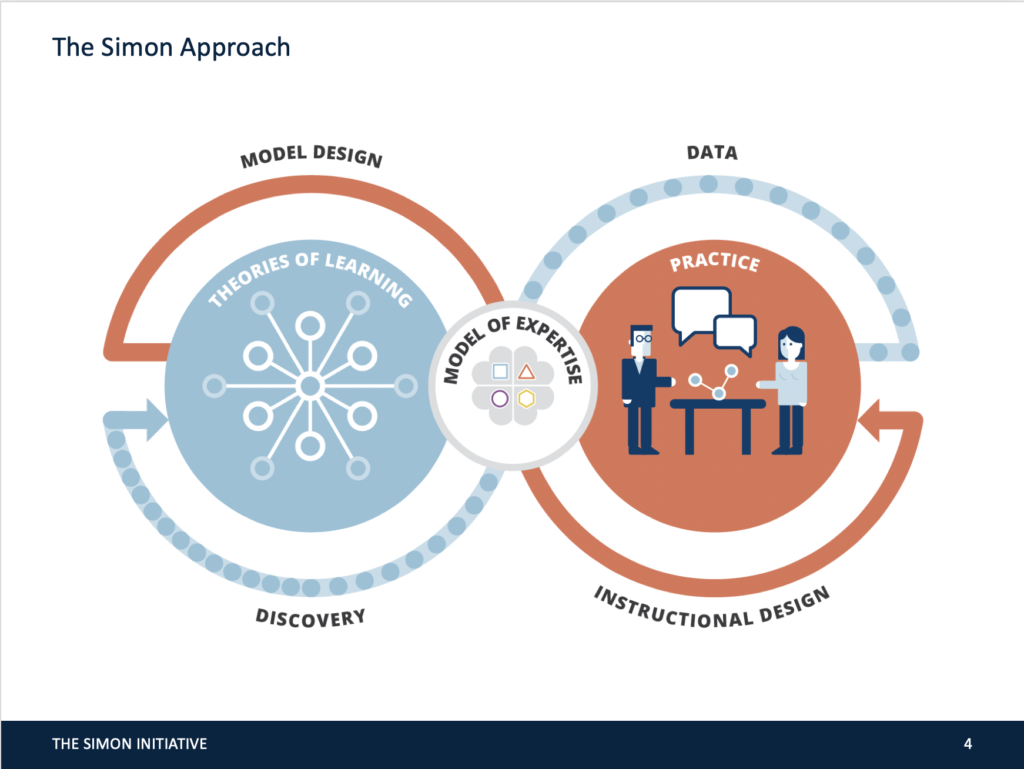
Michael,
Here is where I see the “Learning Engineering” place in a hierarchy of relevant sciences and paradigms.
A. Interdisciplinary Theoretical Sciences (external mathematical models of agent, object, and process)
B. Human Activity and Control Theories (external mathematical models of human, object, and process)
C. Instruction/Learning Engineering (externalized mathematical model of instructor, learner, and process)
D. Empirical Instructional Design (what an instructional process should be)
E. Empirical Learning Sciences (what a learning object is)
Top-Down A–>B–>C approach brings some general theoretical/mathematical frameworks into “learning engineering”.
Bottom-Up E–>D–>C approach brings some specific empirical data to fill in to the “learning engineering” frameworks.
I hope it can help to impose some order in the field.
Thanks
Vlad