This post is part of a series on building a lasting resilience network to support the continuity of quality higher education during times of crisis. In the web version of this post, a table of contents for the series is included at the top of the post.
In my most recent post in this series, I wrote about the kinds of resources that are necessary to create, curate, and distribute during a continuity crisis such as the one we are experiencing now with COVID-19 and made the analogy to the supply chain for healthcare. As the crisis unfolds, we are learning about not just the materials that are needed but how they need to be found or created, vetted for quality, and distributed to where they are needed. Sometimes those resources already exist. A store of N95 masks may be sitting in the crypt of a cathedral. Somebody might invent a way to convert a snorkel mask into a ventilator part, which will need to be tested for efficacy and safety. Or they may develop and test a new ventilator hardware design and release those specifications as open-source, but the plans still need to get into the hands of organizations that are capable of making the device. Maybe thousands of former military personnel volunteer to help, but those volunteers must be matched to hospitals that need them. If we produce needed resources while ignoring the logistical challenges of distributing them effectively, we may end up with serious problems like bidding wars for life-saving supplies. We have a similar problem with educational resilience resources.
Not all resources are the same. We need to think through our supply chain challenges differently for different kinds of resources.
A content resource supply chain
In my most recent post in the series, I broke down the different content resources into four different categories:
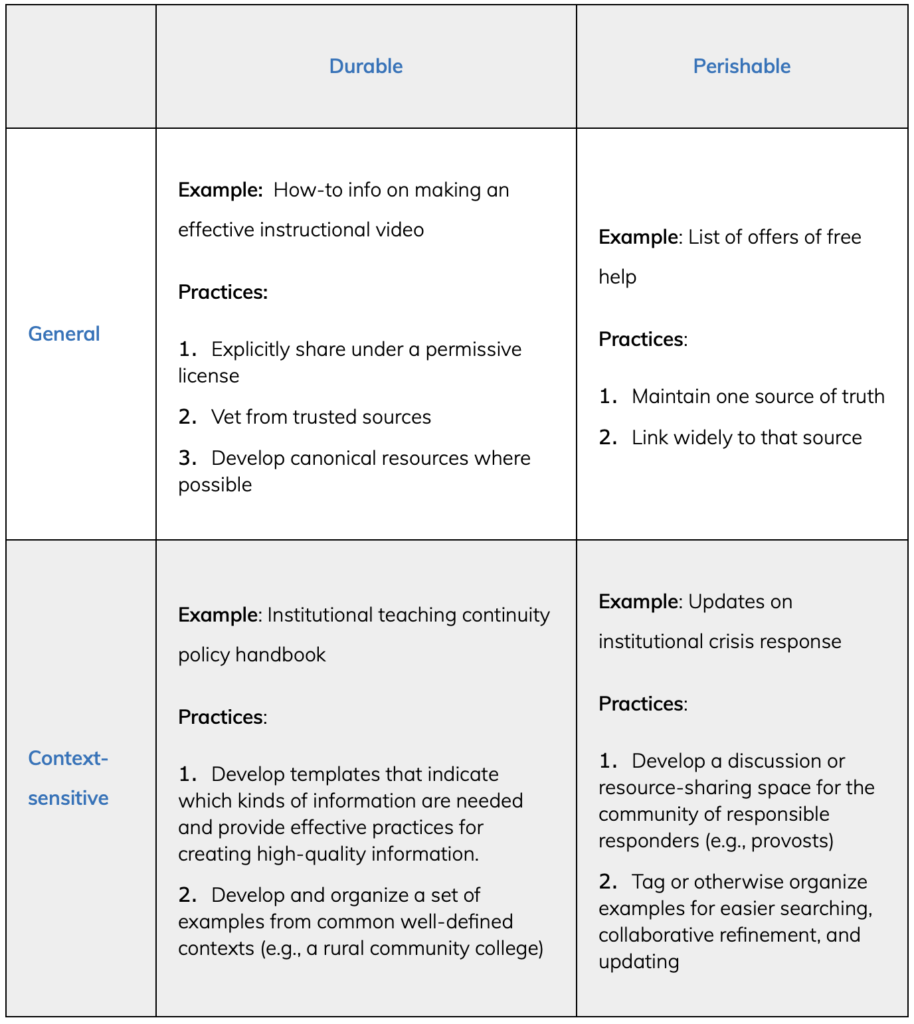
There are basically two types of resources here: (1) content that should be easily shareable and adaptable for point-of-use applications and (2) canonical copies of information that should be maintained in one place by a trusted curator.
To understand how we can improve the supply chain, let’s return to the overlapping Google Sheets mentioned in my first post in the series: the POD list of university continuity web sites (which has 420 entries as of this writing) and Bryan Alexander’s list of universities that are going online during the crisis, including links to each institution’s documentation (which has 279 entries so far). Assuming no overlap, that would give us 679 URLs of web sites that contain a mix of the various types of information and that probably link out to other sites that also contain relevant information resources. Both POD and Bryan’s Future Forum have been effective networks for gathering links to useful information. But sorting through all that information is labor-intensive even within a given network. If we add the goal of sharing information and sorting through the overlap between these networks—and others that may be doing similar aggregation work—the task quickly becomes daunting.
But it is also one that lends itself to technological aid. For example, somebody could create a crawler that indexes all of these sites and applies machine learning to provide a preliminary categorization of resources. “These pages look like policy documents, while these other pages look like instructions on how to teach using webconferencing software.” That information could be cross-referenced with basic IPEDS data like whether the document comes from a community college or a research university.
This preliminary categorization could then be surfaced to human curators, who could verify the labeling by the algorithm, correct any errors, and add relevant metadata that would be important for people interested in using the content that might not be detectable by an algorithm. These curators could be hand-picked for their expertise, or editing could be Wikipedia-style, relying on the wisdom of the crowds. Either way, there needs to be a collaborative online space for reviewing the results of the search and enriching the resulting records. The result would be a single searchable database with a wide range of high-quality machine-sorted and human-curated resources.
We then would need to get those resources to points-of-use, which will be different for different people. It might be a web site of an association like EDUCAUSE. Or an individual university’s web site. Or it might be distributed by vendors. Vendors are a particularly important distribution vector because they are generally very good at reaching particular types of educational stakeholders with targeted messages. One way to do this would be through a faceted search interface like Amazon’s, where you can refine your search results by checking boxes on the sidebar related to different parameters. People could search for what they need and link or embed the resources where they need them. Another approach would be to create a chatbot interface that can be embedded at the point-of-use and scoped according to the same parameters available in the faceted search. For example, you might want to tell the chatbot that it should only display resources related to teaching online when embedded in a web site where that’s what people are most likely to be looking for. These two approaches aren’t mutually exclusive.
A people resource supply chain
One of the interesting aspects of creating a content resource supply chain in this way is that it also enables us to identify experts by attribution. Who authored this particular resource? Who curated it? Who edited it? We can use these connections to enable people who want to help build profiles that make them more findable. And again, we can use machine learning algorithms to make helpful suggestions. “It looks like you have contributed three content resources related to active learning techniques in online courses. Would you like to include that as an area of expertise in your public profile?” In other words, we can back into a kind of LinkedIn for resilience-related help expertise simply by taking advantage of attribution. People become findable—and build their reputations for expertise—based on their contributions.
Mass volunteering is an interesting hybrid case. Suppose, for example, you want to make a list of instructional designers who want to volunteer to help faculty convert their courses in a hurry. The list itself is a content resource. But each name will be linked to a profile. If we really want to go crazy here, we can make it possible for people to issue profile endorsements (or badges) based on the help that the volunteer provided.
All of the technology pieces for this network exist in the world today and could be assembled with a small fraction of the effort that is being put by many well-meaning organizations and individuals that are currently tossing their offerings into the ether and hoping that somebody finds their messages in a (digital) bottle. Furthermore, since these are all resources that people want to publicly contribute, privacy issues should be easy to navigate. (“Would you like to add this to your profile?”) We can create a resilience supply chain if we choose to organize ourselves.