Recently Martin Dougiamas of Moodle has questioned our data analysis for the LMS market. In some useful notes posted at Moodle.com on two recent Future Trends Forums hosted by Bryan Alexander:
Bryan finished the Future Trend Forum by asking for Martin’s thoughts on the recent article by Phil Hill titled: “Whither Moodle?” [edited] which speculated that Moodle’s growth is slowing down and hitting a plateau.
Martin commented that is not the case from what he is seeing and that a lot of the information contained in the article is US-based where there a lot of more LMS vendors and venture capitalists building learning platforms.
While this description from Martin is inaccurate, the issues raised are representative of some of the questions we occasionally get about our data for our LMS market analysis service. I think it would be useful to share a deeper description in public of how our partners at LISTedTECH collect and organize the underlying data.
What We Measure
The market data are organized in a dataset that captures system usage on a per higher education institution basis. For most schools, a campus is equivalent to an institution. But there are also cases where there multiple campuses per university (e.g. University of Minnesota system with five campuses, or DeVry University with dozens of campuses) and the LMS decision is made at the system level. In these situations, one decision will lead to multiple institutions listed in the data. In the US, the definition of an institution is guided by unique identifiers in the Department of Education’s IPEDS data, and each region or even country has its own way of defining institution.
The dataset goes beyond “school X uses system Y”, as it also includes dates of implementation and decommission, usage as primary or secondary system (there may be more than one system in use at a school), and hyperlinks to the public information documenting a system selection or usage. The definition of institutions includes information about its sector (public two-year, private non-profit four-year, etc) as well as student enrollments.
How We Measure
Looking deeper at LMS selection, there are multiple layers of data gathering at different intervals. Some of the sources:
- Extensive search engine notification such as Google Alerts on product keywords in multiple languages;
- URL and domain scrapers looking for system information at official school websites; and
- Targeted human-directed searches.
Each new data point is verified by someone using the associated hyperlinks tied to selection or usage data.
Our North American data is essentially saturated, in that we know the vast majority of degree-granting institutions based on US Department of Education data or Canadian provincial governmental data. We have well above 90% of all schools in the dataset.
For the global regions outside of North America, we are building up the dataset and do not have saturated coverage yet. For example, in Europe we estimate that we have 60 – 75% of institutions. We have less than that in Latin America and more than that in Oceania.
Where feasible, we include on-the-ground subjective coverage by visiting the global regions, testing theses, finding out unique context, and finding local sources who can provide QA to our data.
Besides our home base of North America, we have made multiple trips to Europe and Latin America thus far, and we are currently arguing about who gets to visit Australia and New Zealand.
We plan to expand coverage to additional regions as we develop at least 30% coverage of institutions and have time to do additional research to back up our analysis.
Degrees of Uncertainty
Because higher education data is lumpy and based on extended implementation times, we offer the following caveats:
- Market share information provided in percentages and trends are more reliable than absolute counts outside of North America. When we do provide absolute numbers, we advise caution for readers or subscribers to not over-interpret the absolute numbers, at least without us providing additional details to keep the data in context.
- We typically separate North American data from Rest of World data (Europe, Latin America, Oceania) to avoid problem of North America numbers dominating aggregates and obscuring important regional differences.
- When we have system usage information but do not have accurate implementation dates (per month or quarter), we assign these system records to June. Therefore the summer data for new systems will appear artificially high. We currently have implementation dates for approximately 75% of the listed LMS records.
- Put another way, annual data is more reliable (i.e. without additional data collection noise) than half-year or quarterly data. The more-granular data is provided to certain subscribers, but we take great care in attempting to describe sources of “lumpiness” in the data that should be understood for any analysis.
Overall, we have LMS data for 4,523 institutions in the US and Canada and 8,824 institutions worldwide.
Back to the Future (Trends)
To see these issues with an example, consider the updated chart of new implementations that led to the Future Trends Forum discussion described above.
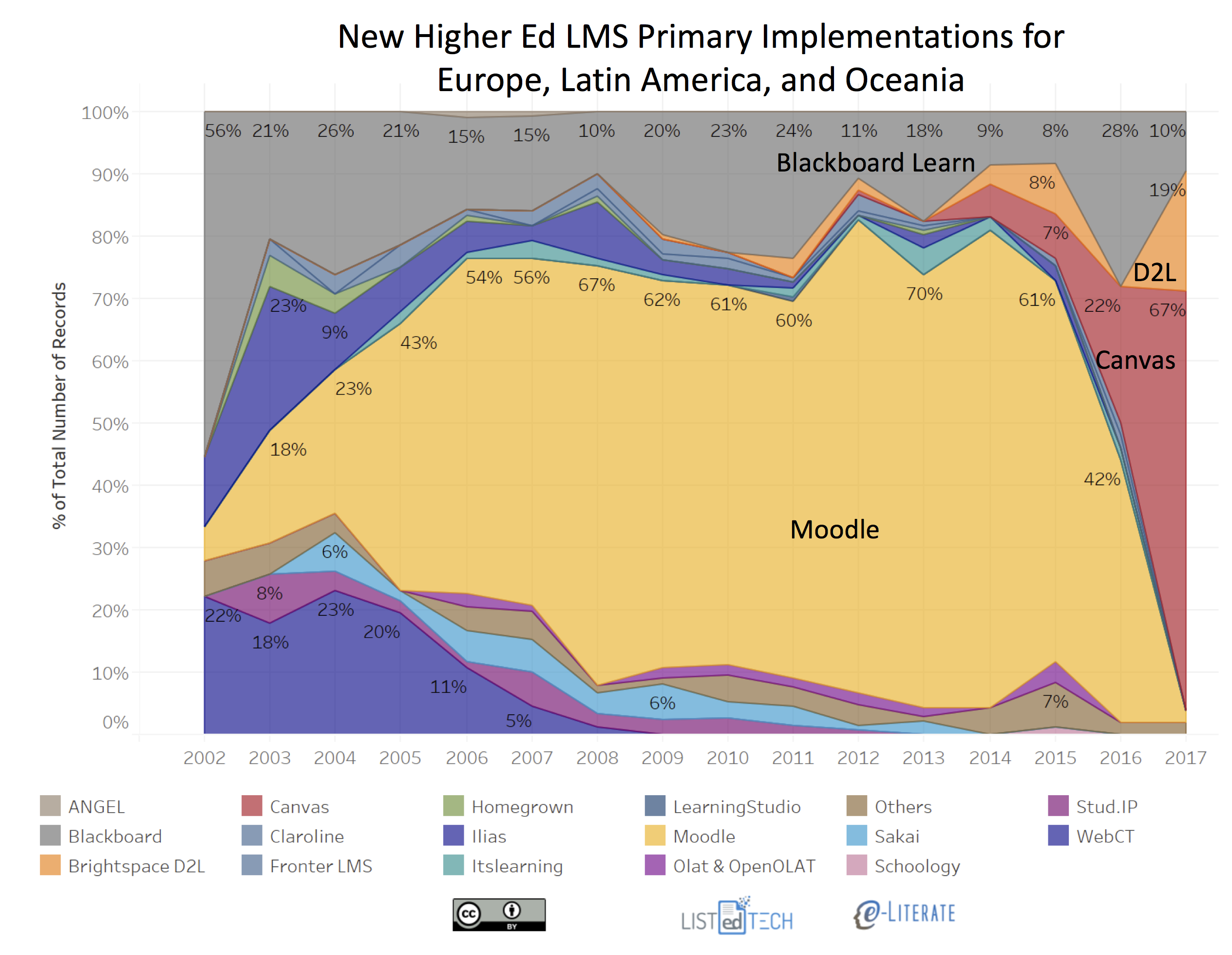
What is relevant to the dataset for this chart:
- The data is based not on North American data – it is based on data from Europe, Latin America, and Oceania (Australia, New Zealand, and surrounding island countries).
- The data comes from public sources per institution as described above and does not come from vendors;
- The data is for primary systems – the official campus LMS; and
- The caveats listed above should apply. Note that we identified a new trend early in 2017 (collapse of Moodle new implementations) that we can update with data through 10 months of the year – the data today is more solid than it was in early summer.
I hope this description will answer some of the questions people have asked about our data.
Hi guys,
My main issues with your blog articles about the “LMS Market”, guys, are:
1) you reference “the LMS Market” everywhere (even in this article) when in fact you only mean higher ed, excluding K12, workplace, military, government, individual departments, individual teachers, and a lot of other minor sectors;
2) as you basically repeat in this article, you do NOT have good information on areas outside the US. Asia, Africa, Middle East are not even mentioned. (A reminder: the US has 4.25% of the world’s population, EU is less than 10%). This natural bias is not usually made clear in your graphs and articles, however. I don’t think my statements were inaccurate at all.
Both of these facts directly reduce Moodle figures in your data, as Moodle, being a true Open Source project, is widely used worldwide in 110 languages AND in every sector.
I also note you’ve also ignored our recent major investment news which I thought might have been interesting to you. One hopes this is not just because we are not a US-based company. 😉
Cheers,
Martin